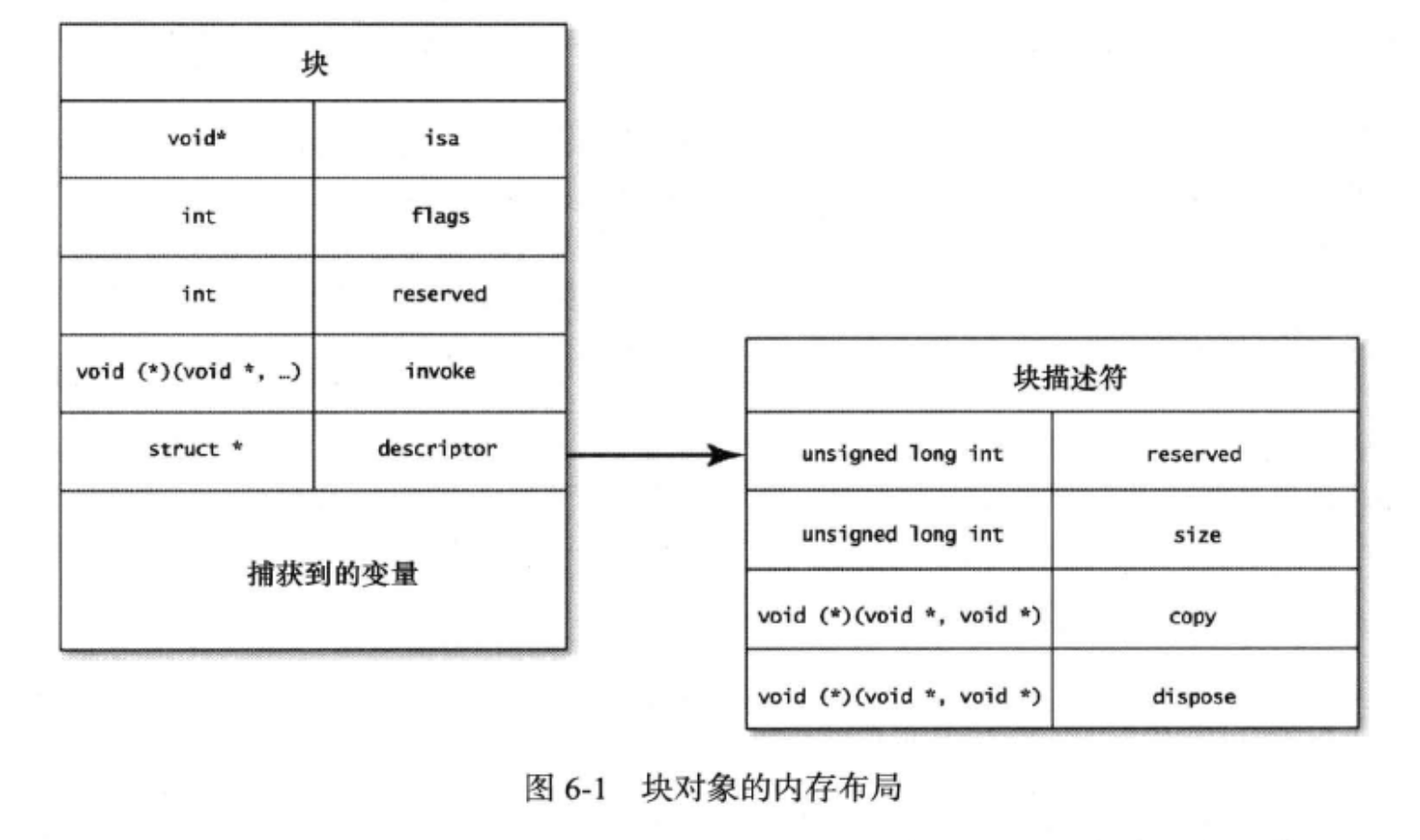
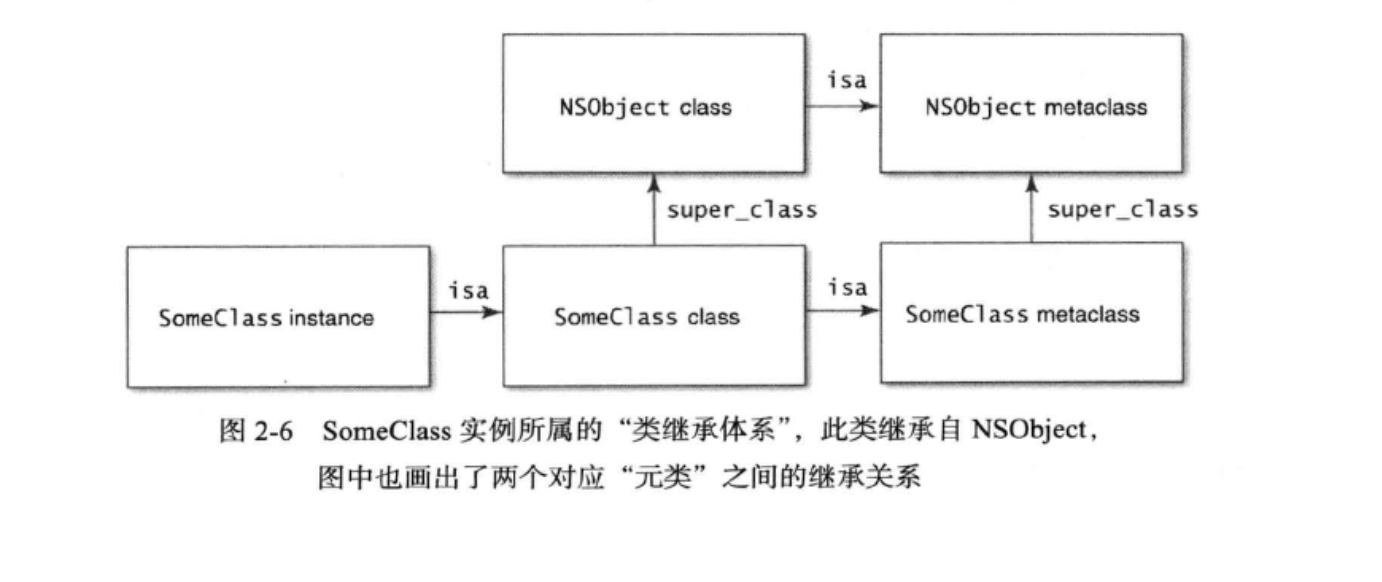
在 Swift 高阶使用中,map、fitter、reduce 是很常见的操作,能使代码干净整洁。在理解其概念之前,先要明白泛型的概念。
泛型
定义 computeIntArray 函数,接收一个数组,并返回其元素的2倍组成的另一个新的数组。但此函数只支持 Int 类型。如果换成其他类型则不适用,所以这里考虑用泛型来解决。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34func computeIntArray(xs: [Int], transform: (Int) -> Int) -> [Int] {
var result: [Int] = []
for x in xs {
result.append(transform(x))
}
return result
}
func doubleArray(xs: [Int]) -> [Int] {
return computeIntArray(xs: xs) { x in x * 2 }
}
doubleArray(xs: [1, 2, 3])
// 换成 bool,则会出现编译错误
func isEvenArray(xs: [Int]) -> [Bool] {
return computeIntArray(xs: xs) { x in x % 2 == 0 }
}
// 使用泛型支持各种类型,进行抽象,对于任何 Element 的数组和 transform: Element -> T 函数,它都会生成一个 T 类型数组
func map<Element, T>(xs: [Element], transform: (Element) -> T) -> [T] {
var result: [T] = []
for x in xs {
result.append(transform(x))
}
return result
}
func genericComputeArray<T>(xs: [Int], transform: (Int) -> T) -> [T] {
return map(xs: xs, transform: transform)
}
genericComputeArray(xs: [2, 3, 4]) { x in x * 2 }
map
map函数能够被数组调用,还接收一个闭包参数,将数组中的每一个元素依次作用于该闭包,并返回一个新的数组。
上面的例子中,将泛型函数写成全局函数固然能够完成任务,但是为了避免写入顶层函数实现。将此函数定义为 Array 的扩展更合适。
1 | extension Array { |
fitter
与 map 函数类似,fitter 函数也可以接收一个闭包作为参数,同样可以避免函数为顶层实现:
1 | extension Array { |
reduce
reduce 函数将变量初始化为某个值,对数组中的每一项进行遍历,最后一某种方式更新结果。
1 | extension Array { |
flatMap
flatMap 与 map 类似,区别是若元素值不为 nil 的情况下,flatMap 能将可选类型转换为非可选类型:
1 | let array = ["123", "", "4567"] |
Any 与 泛型
尽量避免使用 Any 类型,因为使用 Any 类型会避开 swift 的类型系统。比如将 noOp 函数返回值设为 0 会导致类型错误。此外,任何调用 noOpAny 的函数都不知道返回值会被转换为何种类型。而结果就是可能导致各种各样的运行时错误。
1 | func noOp<T>(x: T) -> T { |